https://github.com/deepseek-ai/DeepSeek-V3.2-Exp/blob/main/DeepSeek_V3_2.pdf
instead of doing attention for all tokens in the sequence they do it for selected tokens. “we will do mixture of experts vertically” basically. they pass the tokens through a cheap filter first and only do attention calc over the top k tokens from the original sequence.
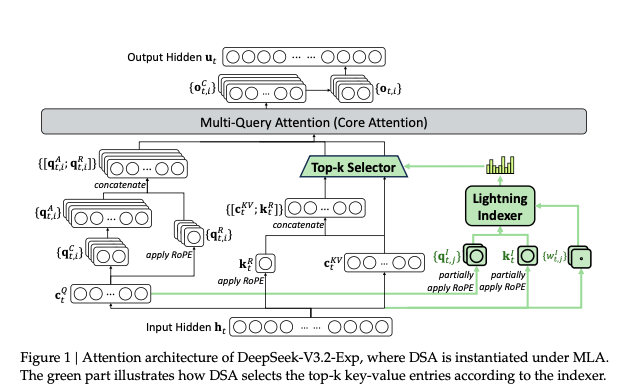
it consists of two components :
- lightning indexer
- finegrained token selector
lightning indexer
it computes the index scores for all the query tokens in the sequence using the formula :
where: = number of indexer heads and meaning, query vector for head j at position t and learnable weight for head j derived from query token for the constant. is the key token from the previous token at .
after which it calls the fine-grained token selection mechanism with these scores to extract the k,v (s) of those tokens.
do they use the same lightning indexer for all attention blocks or different one for each new layer? (i think per layer)
training
they train it on top of v3.1 terminus. they do it in two steps step 1: dense warm up
- freeze all the weights only run the index q and k projector parameter and the constant param weights.
- do it for all the tokens in the entire llm to mimic the attention weights.
and step 2: sparse training
- turn on all weights and run it with lightning indexer to adapt to sparse attention over all
dense warm up
they first get all the attention scores for the token sequence and heads and then add those up to an aggregated attention score to which they normalize it across the total aggregation dims so something like.
Position t=100, looking at previous 99 tokens: Main attention says: Head 1: [0.01, 0.02, ..., 0.15 (pos 50), ..., 0.03] Head 2: [0.00, 0.01, ..., 0.20 (pos 50), ..., 0.02] ... Head 128: [0.02, 0.00, ..., 0.10 (pos 50), ..., 0.01] Aggregate: [0.50, 0.80, ..., 12.5 (pos 50), ..., 1.2] Normalize: p_{100,:} = [0.005, 0.008, ..., 0.125 (pos 50), ..., 0.012] ↑ This is the TARGET distribution
then they train the indexer weights to match this distribution by using KL divergence as a loss (i have no idea why i don’t see why missing bits is more intuitive then matching distribution scores).
 lr = , steps = 1000, 16 seq batch of 128k tokens each : 2.1B tokens
lr = , steps = 1000, 16 seq batch of 128k tokens each : 2.1B tokens
sparse training
two steps inside that step 1: get the top k tokens based on the index scores and get the target distribution for them (like in the prev method) then get indexer scores for them and do a KL div loss on that. step 2: do a cross entropy loss on the LLM itself
this helps the model adapt to the new top_k tokens that it gets and update the indexer algo too while live

i do however have some doubt as to they won’t be training the indexer separately cuz that would require running the LLM for attention distribution parallely (damn).
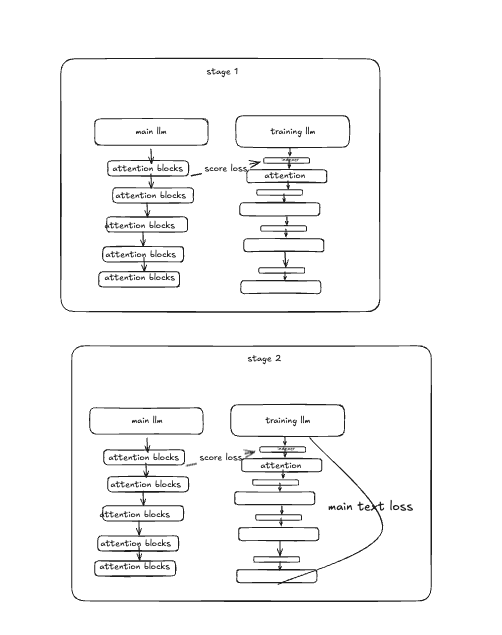
each attention block has it’s own lightning indexer what happens if we use one for all?
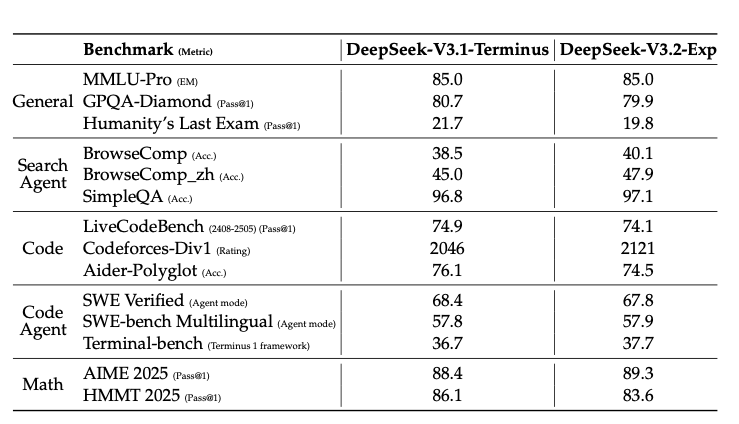
results
the performance was same after some post training and the bench numbers are same as before
 the main improvement is in the massive inference cost savings
the main improvement is in the massive inference cost savings
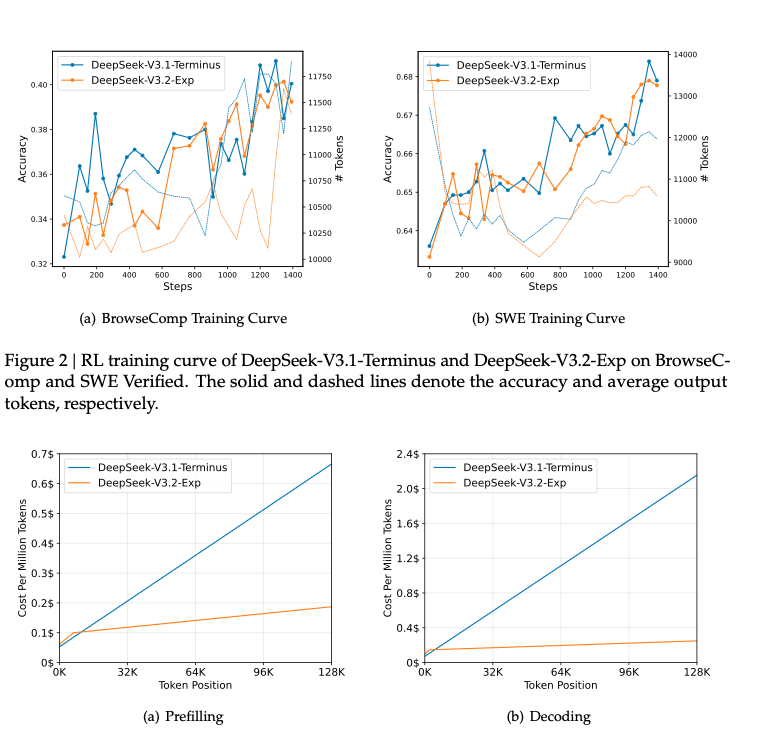
model size and token calculation
now i don’t imagine the model is much bigger than the original size except for the lightning indexer params which are just projection matrices
model is 685B params the original was 671B params so they added about 80k model more which is an mixture of experts model so active were around 37B in a forward pass.
we want a small model to verify this
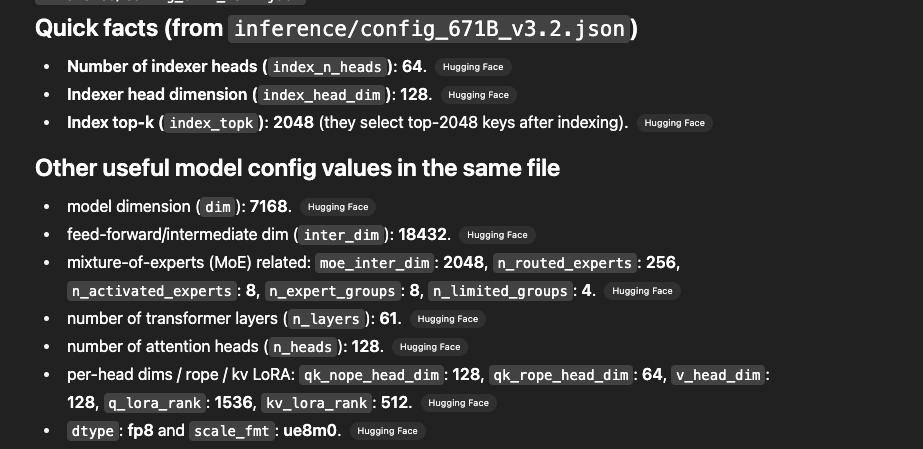 indexer heads are just half that of attention heads.
indexer heads are just half that of attention heads.