https://youtu.be/o_3mboe1jYI?si=b5_OqJImrYWqi_pk
when passing information in a neural network often times in order to minimize the loss the neural network forgets that its original purpose was to optimise for approximating the function this leads to certain problems
assume this is our function
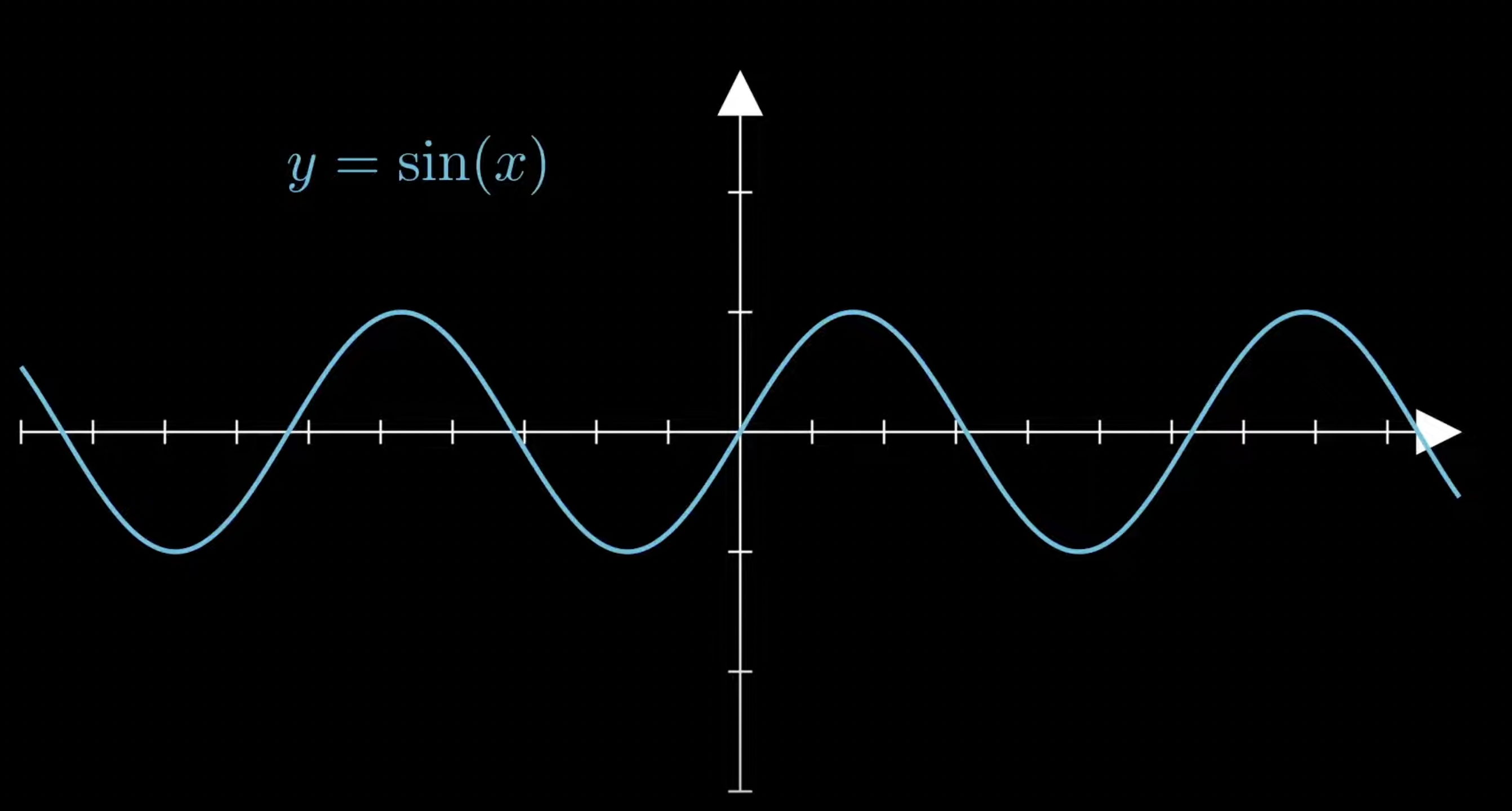 but when using activation functions we get outputs like these
but when using activation functions we get outputs like these
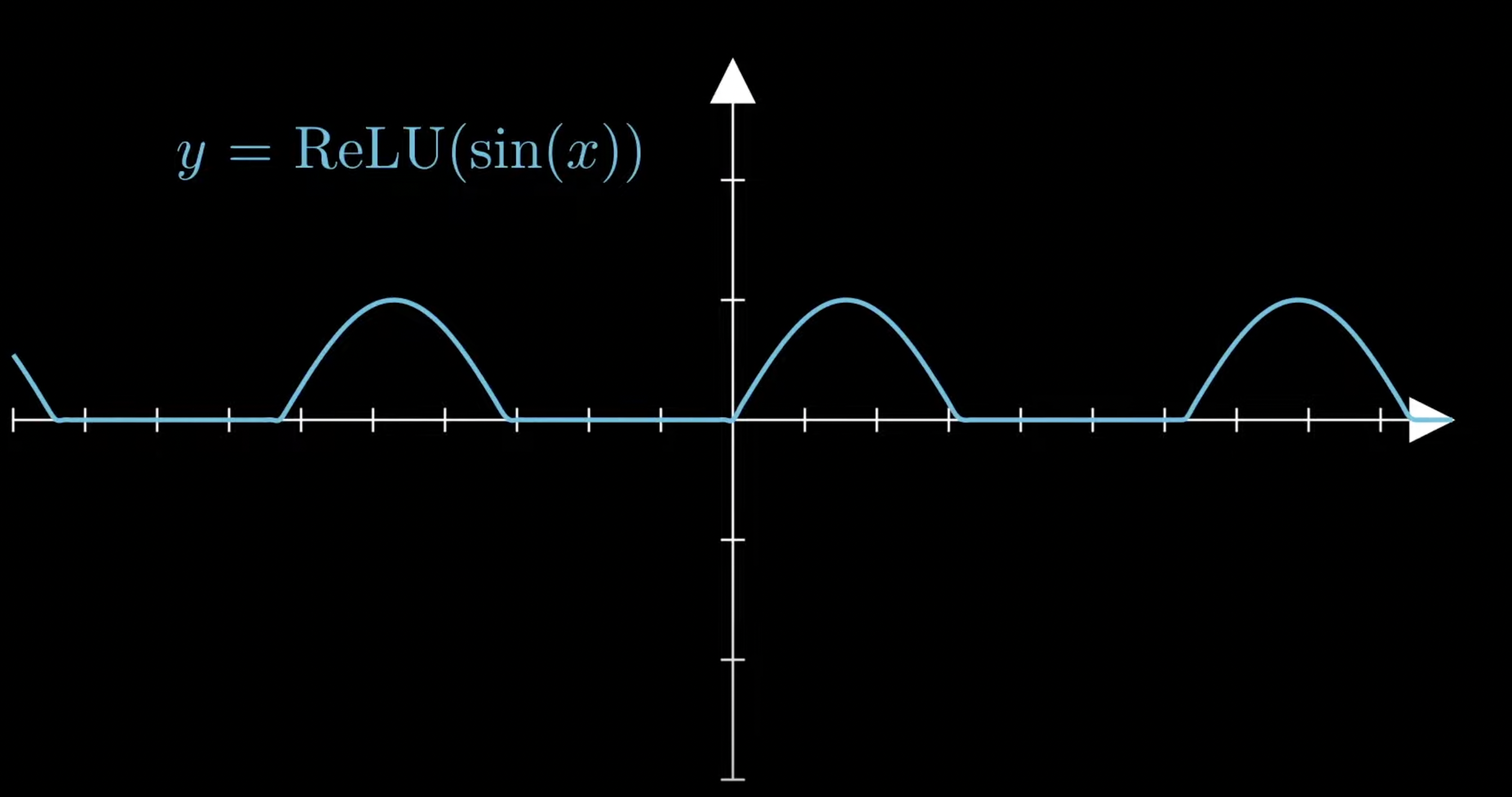
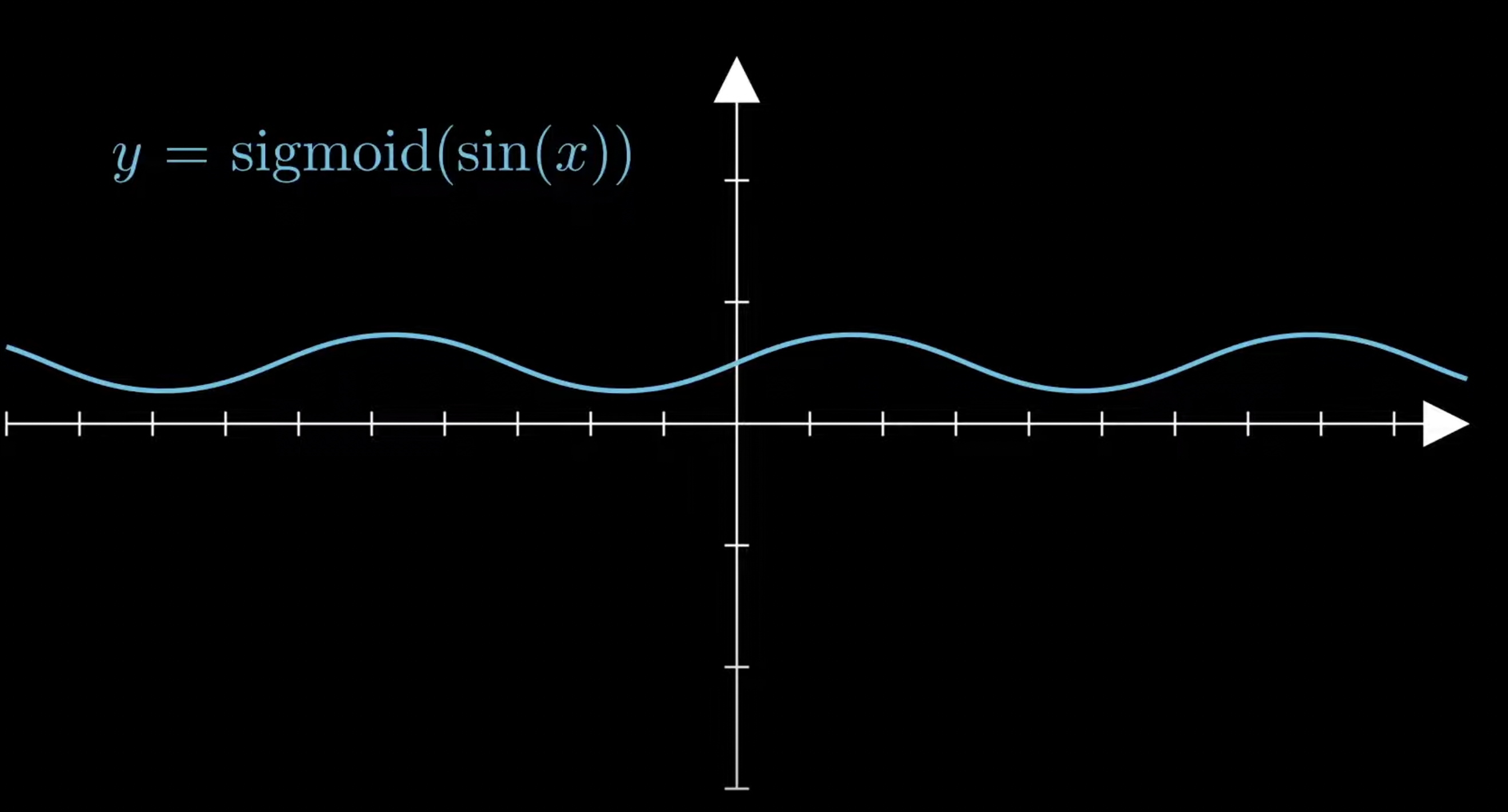 these are sort of trivial though as they can be solved using a better activation function but that is because we know the defined function here when we have unsupervised learning we don’t really know what the function looks like and what the ideal activation function looks like.
plus when trying for it to perform better on different types of data we make different architectures all simplifying the graphing function hence we get what we call A vanishing gradient
so we use residual networks
the essential idea is to pass unprocessed data from some prev layers and pass it onto the next ones so that we keep traces of the original ones
these are sort of trivial though as they can be solved using a better activation function but that is because we know the defined function here when we have unsupervised learning we don’t really know what the function looks like and what the ideal activation function looks like.
plus when trying for it to perform better on different types of data we make different architectures all simplifying the graphing function hence we get what we call A vanishing gradient
so we use residual networks
the essential idea is to pass unprocessed data from some prev layers and pass it onto the next ones so that we keep traces of the original ones
This problem was tackled in the paper ResNet from 2015
lets assume you have a stack of layers and you have the middle most layers we can assume at this point in the neural network we have pretty much lost the original trainign signal so what do we do to fix it we just add the raw data from the first layer to the middle layer and then from the middle layer to the last layer
this opens to the idea of residual block
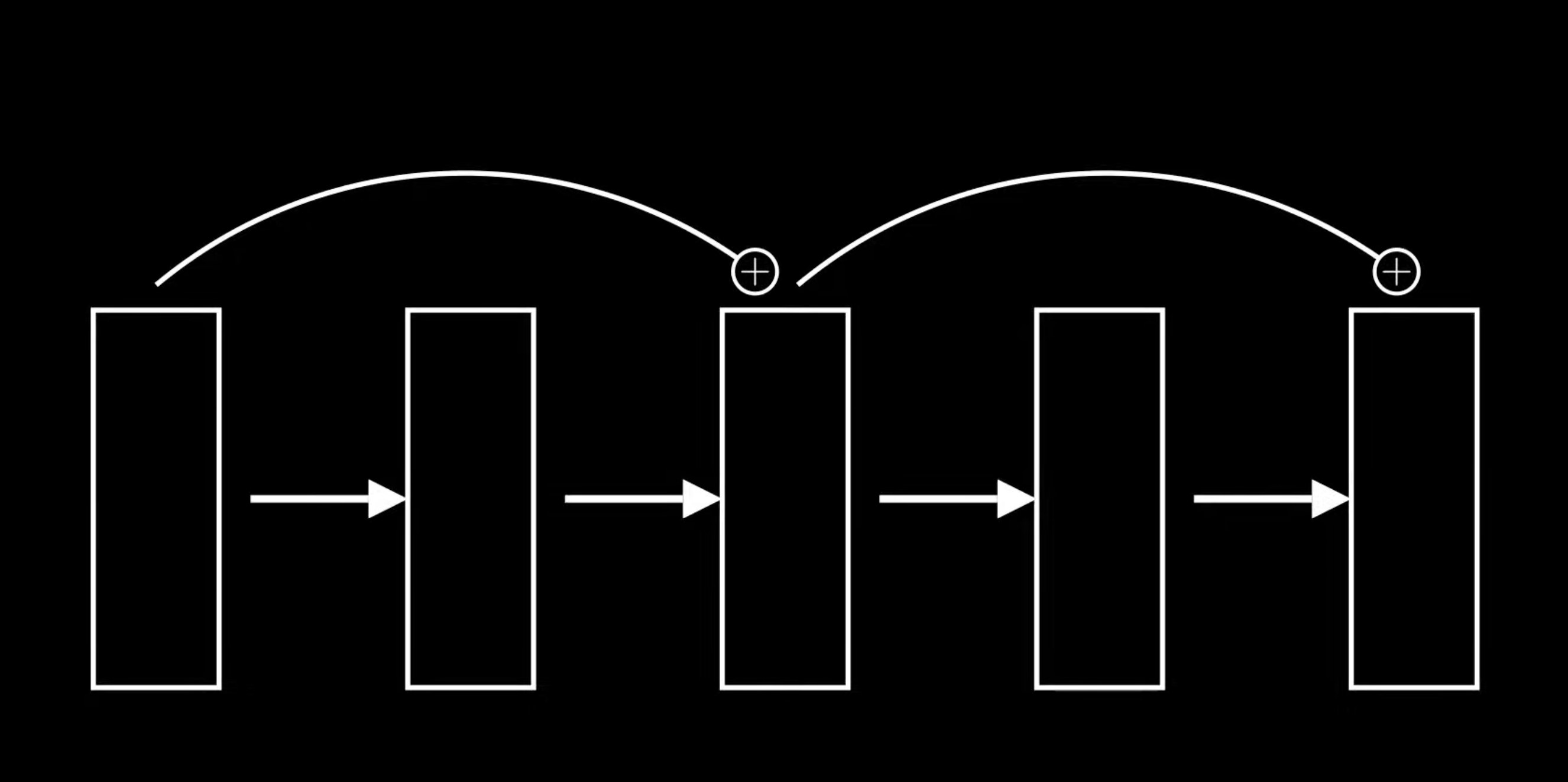
ResNet block
basically this when we have a neural network and it goes through the block everytime we have a small idea of changing its original function change we add a the original log
we need to do this before the dimensionality change of this block because the original data and the processed data should be of the same shape
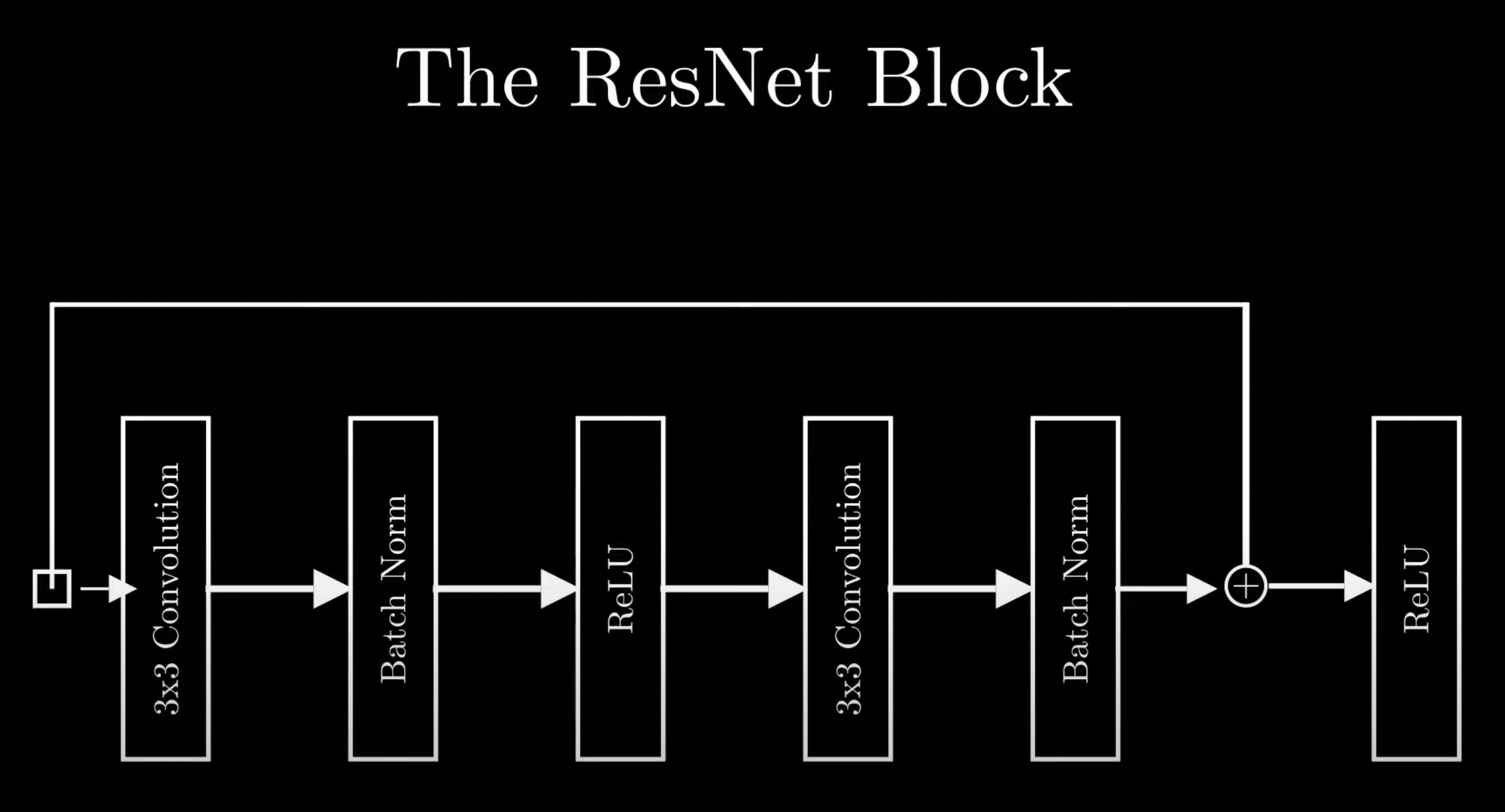 when adding these residual connections we add the entire batch and not just specific sample so if you have 10 tokens and 10 are processed all 10 are then in passed
this must change the dimensions though hmmm.
when trying to change the dimensions for different dimensions of input and output it gradually reduces the dimensions
instead of adding the entire input block from start to end we can add in between blocks every few blocks it then gradually learns to attain it.
there must be something done in the code though to trim the dimensions effectively since just arbitrarily removing stuff might result in random noise
i assume it depends on what kind of data you are working on
when adding these residual connections we add the entire batch and not just specific sample so if you have 10 tokens and 10 are processed all 10 are then in passed
this must change the dimensions though hmmm.
when trying to change the dimensions for different dimensions of input and output it gradually reduces the dimensions
instead of adding the entire input block from start to end we can add in between blocks every few blocks it then gradually learns to attain it.
there must be something done in the code though to trim the dimensions effectively since just arbitrarily removing stuff might result in random noise
i assume it depends on what kind of data you are working on