https://jalammar.github.io/illustrated-transformer/ https://www.youtube.com/watch?v=kWLed8o5M2Y&t=7s
you already know the basics we will try to cover everything you haven’t and idea of until now
explaination of why each part is done at the end of this in terms of neural networks and graphs etc ig
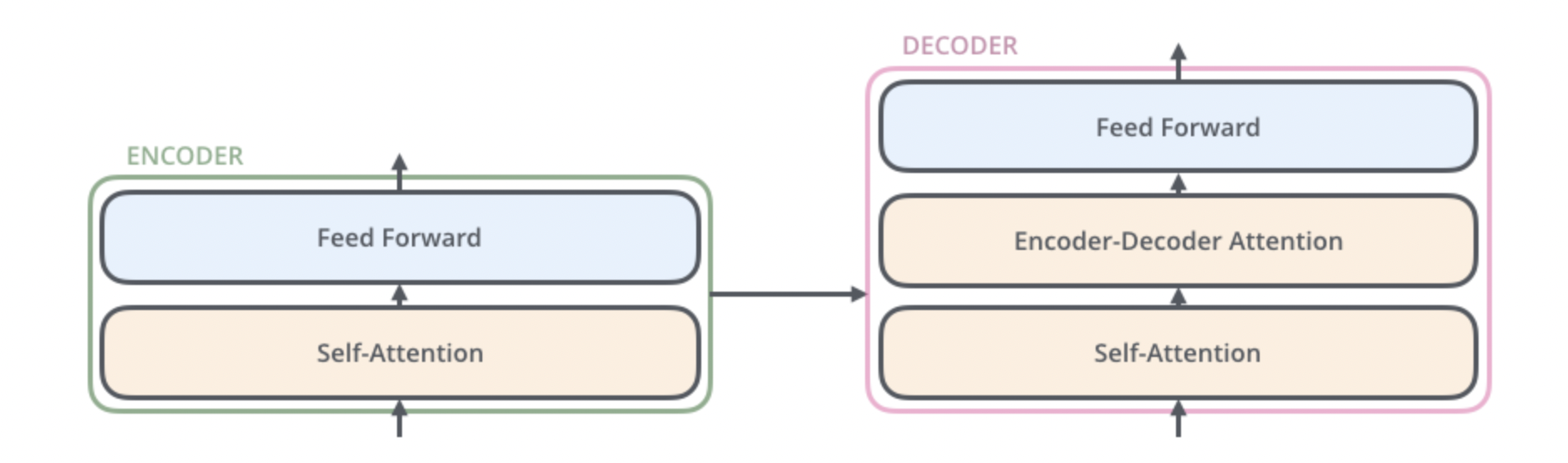
two components encoding decoding each have have a stack of encoders/decoders
encoder
the encoders are all identical in structure (yet they do not share weights). Each one is broken down into two sub-layers: the encoder’s inputs first flow through a self-attention layer – a layer that helps the encoder look at other words in the input sentence as it encodes this is waht it looks like but uts tons of stacks
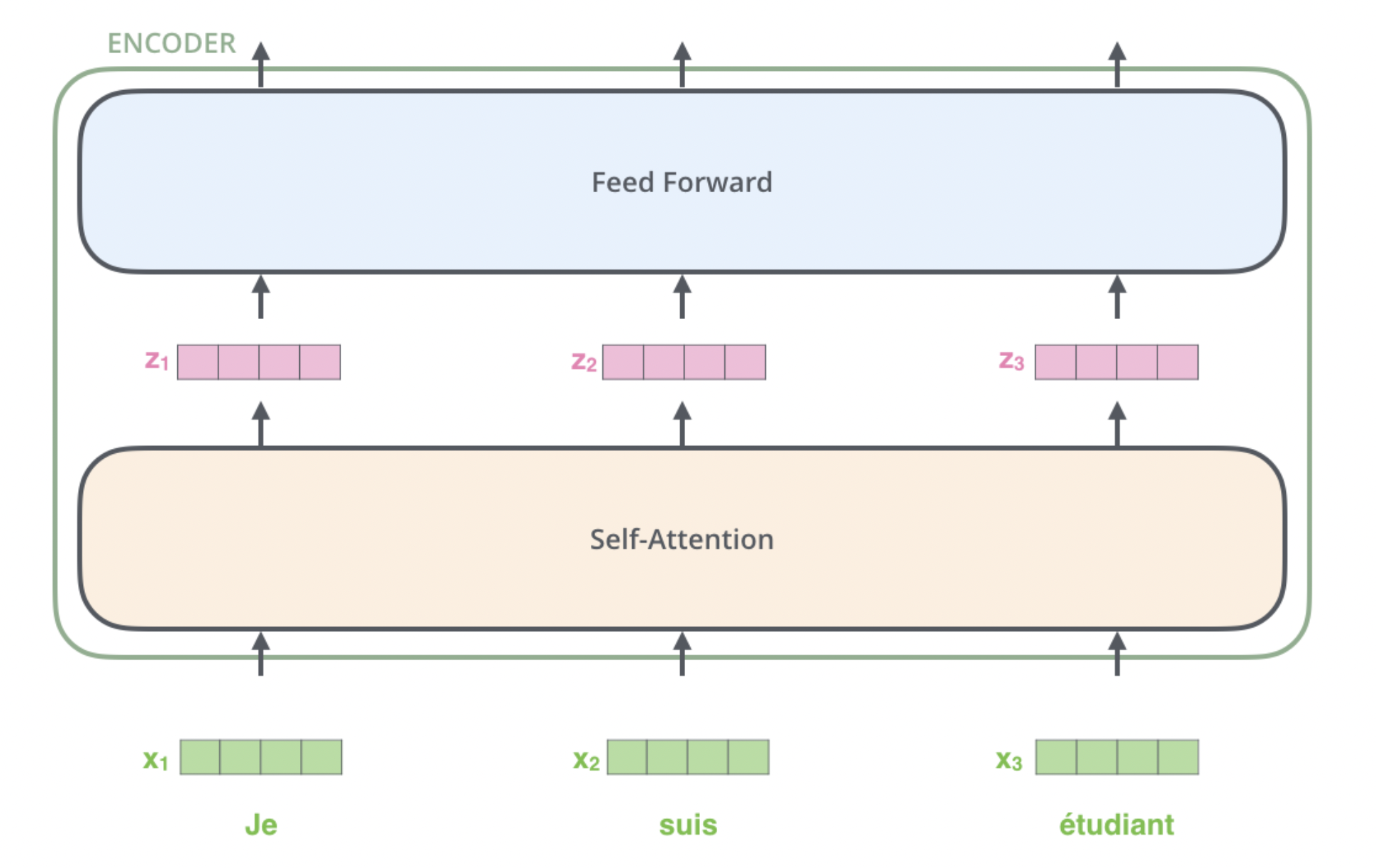
 this is how words go into the block
each word is technically independently going as a tensor each and we add the positional encoding to make sense of its positions etc
this is how words go into the block
each word is technically independently going as a tensor each and we add the positional encoding to make sense of its positions etc
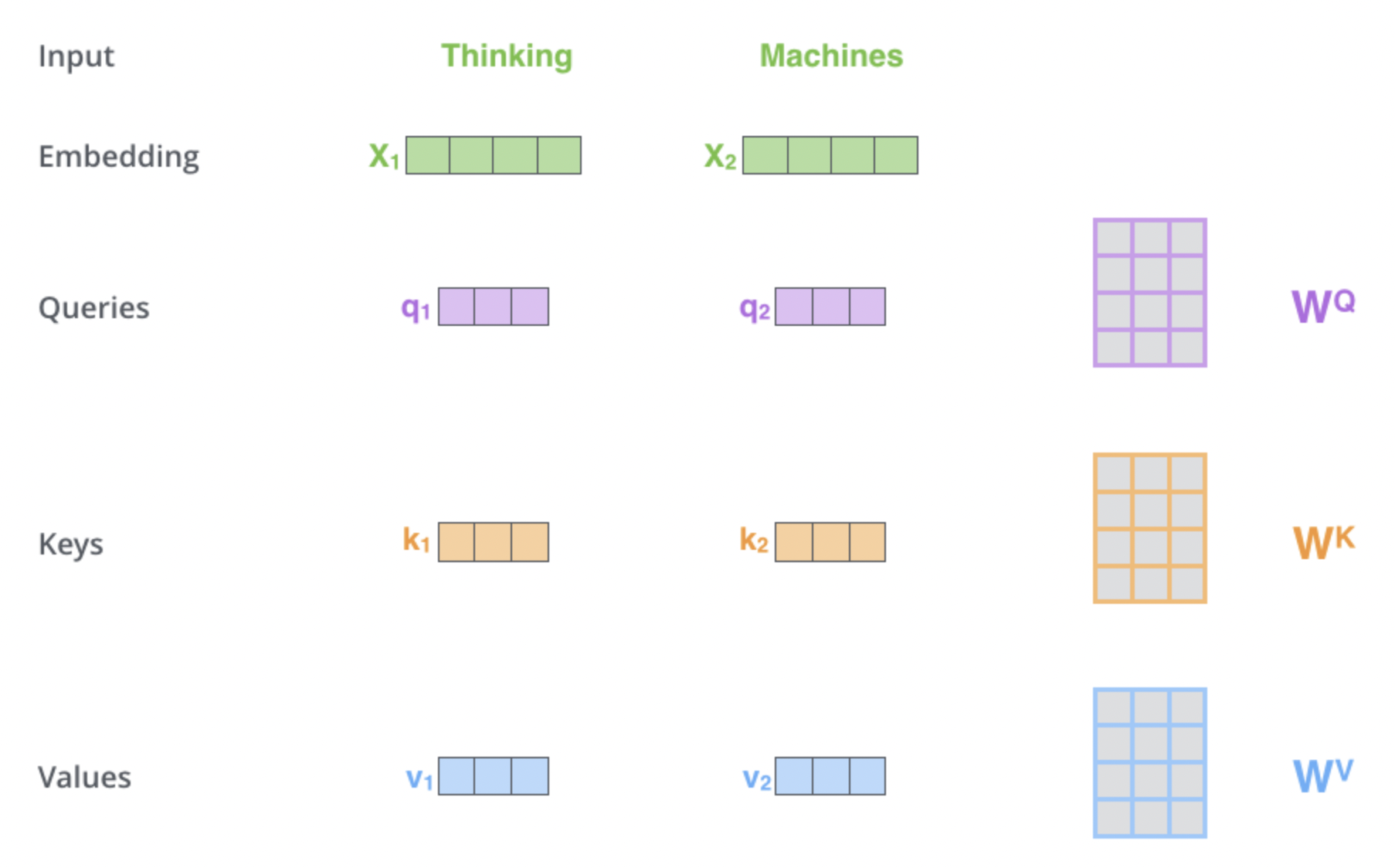
self attention:
the encoding of words creates three vectors these vectors are created by multiplying the embedding by three matrices that we trained during the training process.
- Query (Q): Represents the “question” or “focus” of the current word/token. It’s used to query other tokens for relevance. this is more like what does this word refer to in context of
- Key (K): Represents the “identifier” or “label” of each token. It’s used to match against the query to determine relevance. this as said is like the label (like in a dictionary when you try to find a word by that word)
- Value (V): Represents the actual “content” or “information” of each token. It’s what gets aggregated based on the attention scores. (this is the actual meaning of the word from the dictionary) these essentially capture the entire meaning of the language latent space or manifold space these are the vector space containing all dim that define the language
this is how the attention for each word is calculated agains every other word in the sentence
this gives us an attention score over each word
The score is calculated by taking the dot product of the query vector with the key vector of the respective word we’re scoring. So if we’re processing the self-attention for the word in position #1, the first score would be the dot product of q1 and k1. The second score would be the dot product of q1 and k2.
 after this we normalize the scores and pass them through softmax so the value is positive and between 0-1
This softmax score determines how much each word will be expressed at this position. Clearly the word at this position will have the highest softmax score, but sometimes it’s useful to attend to another word that is relevant to the current word.
next the output vectors of each of these attention scores are then multiplied by there value vector
(we use the same value vec from the same word that we used key from)
after doing this all the vectors with the same original query is added together
after this we normalize the scores and pass them through softmax so the value is positive and between 0-1
This softmax score determines how much each word will be expressed at this position. Clearly the word at this position will have the highest softmax score, but sometimes it’s useful to attend to another word that is relevant to the current word.
next the output vectors of each of these attention scores are then multiplied by there value vector
(we use the same value vec from the same word that we used key from)
after doing this all the vectors with the same original query is added together
For Word A:
| Attention Weight | Value Vector | Weighted Value |
|---|---|---|
α_AA | V_A | α_AA * V_A |
α_AB | V_B | α_AB * V_B |
| Sum | Output_A = α_AA * V_A + α_AB * V_B |
For Word B:
| Attention Weight | Value Vector | Weighted Value |
|---|---|---|
α_BA | V_A | α_BA * V_A |
α_BB | V_B | α_BB * V_B |
| Sum | Output_B = α_BA * V_A + α_BB * V_B | |
| and that is self attention calculation | ||
| the outputs are then passed through the next feedforward to the next enoder block and so on |
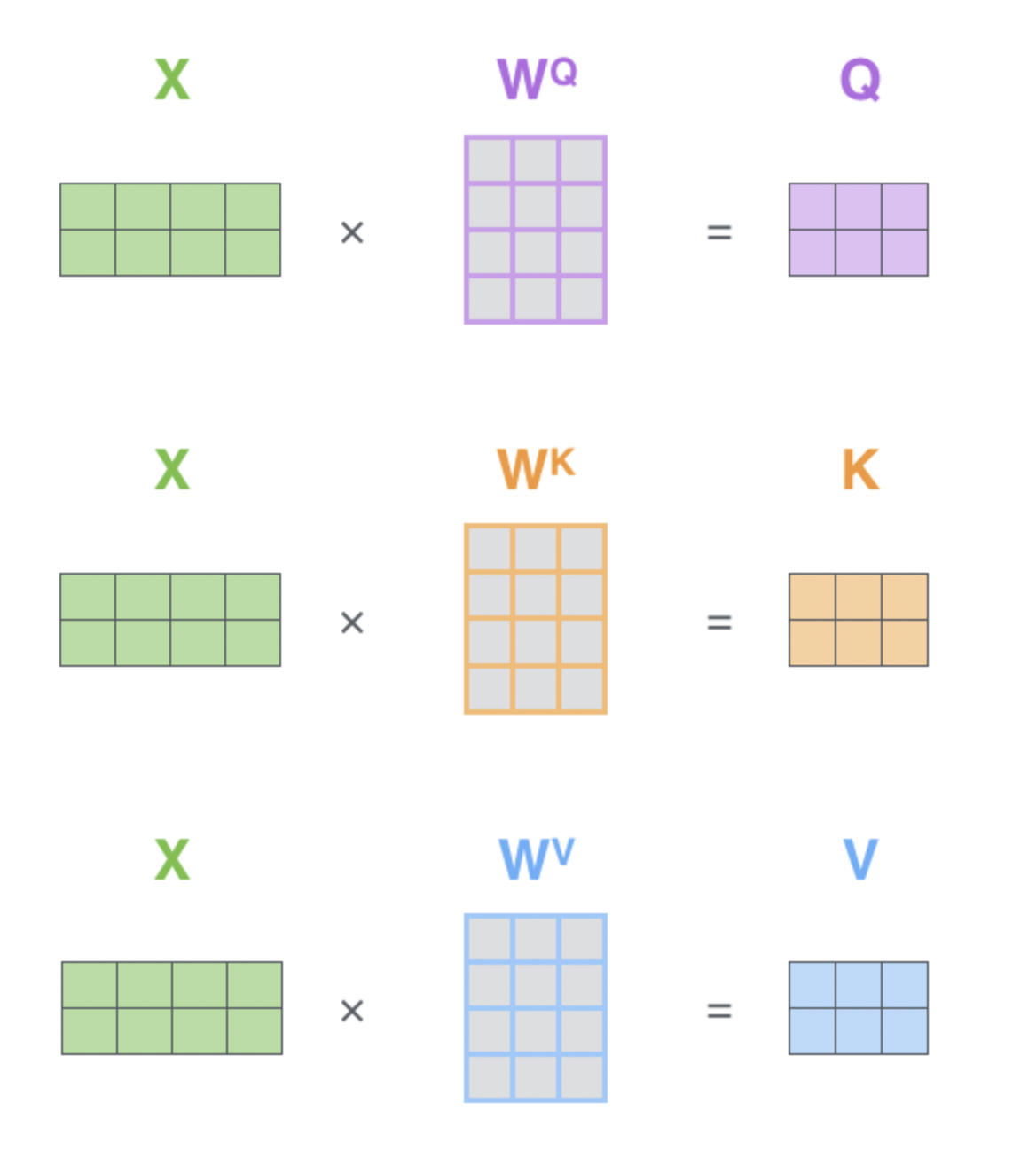
Matrix calculation of self attention
this is how we get the qkv for each word
W^q and so on stands for the weight matrices converting them
 Finally, since we’re dealing with matrices, we can condense steps two through six in one formula to calculate the outputs of the self-attention layer.
Finally, since we’re dealing with matrices, we can condense steps two through six in one formula to calculate the outputs of the self-attention layer.
 that is actually just it
that is actually just it
Multi headed attention
this is a difficult one the jay alamar explaination is pretty cool actually so follow that and i explain it more simply here first we have. mutliple attention head so for each word we get a different output score from each attention head that we then contacatenat into one
- For each word, take the outputs from all attention heads and concatenate them into a single vector.
- If each head produces an output of size
d_headand there arehheads, the concatenated vector will have sizeh * d_head. Pass the concatenated vector through a learnable linear layer to project it back into the original embedding dimension (d_model). this puts it back into the same loop from the starting of feedforward network here is the visualisation of the entire process for the self attention process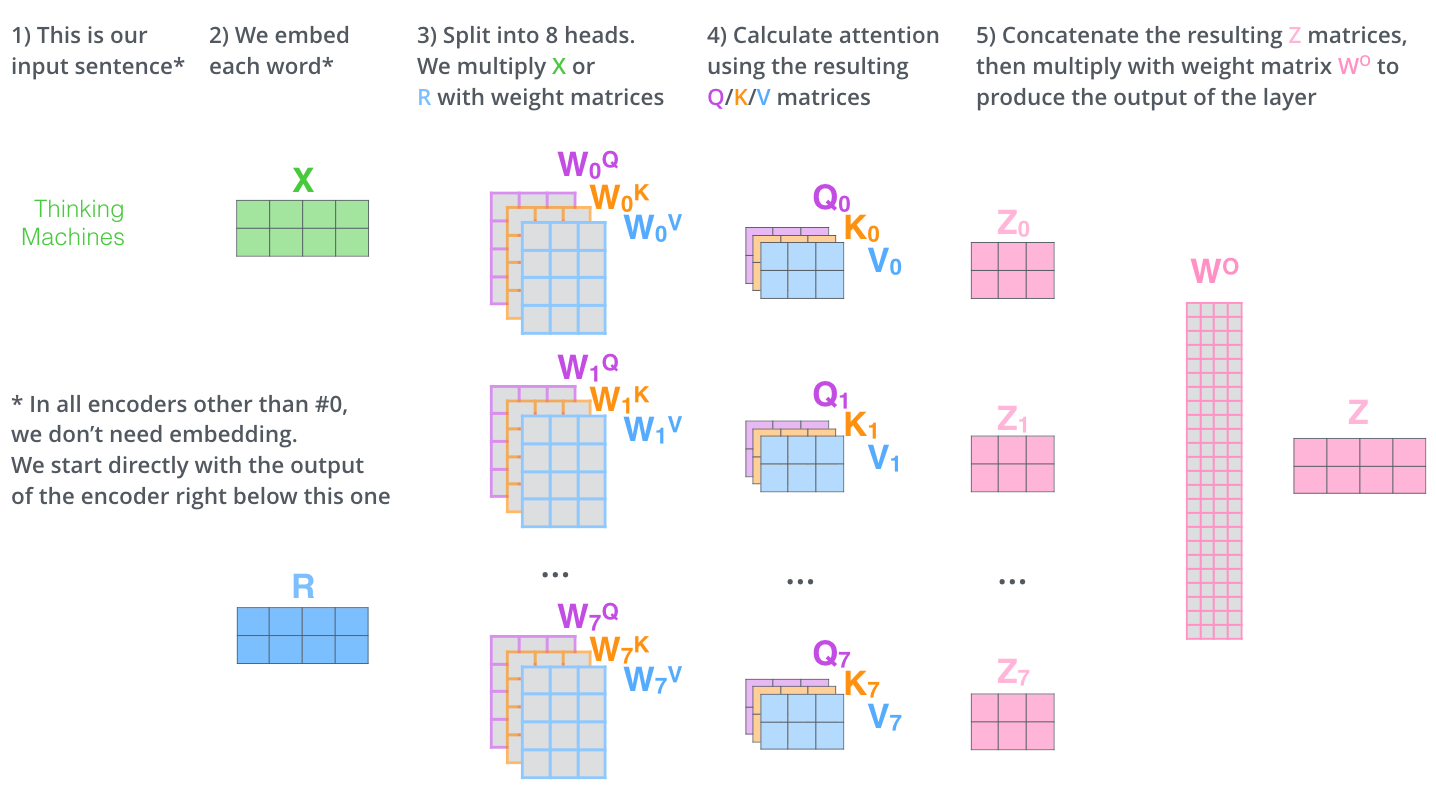
this is multi headed attention btw
positional encoding understanding where is what
to understand what the position of what word is where we need to hack something since all of the attention and feedforward process is parallel we need to find the way to signify the positions of the words when computing it
to address this, the transformer adds a vector to each input embedding
these are a specific pattern trained with the model
it helps it determine the position of each word, or the distance between different words the idea is adding this gives depth to the vector of what other words are relative to each other![]()
final conclusion of encoding block
each sub-layer (self-attention, ffnn) in each encoder has a residual connection around it, and is followed by a layer-normalization step.
this is the entire encoding block
![]()